
The Fokker-Planck forward equation is an important tool to calibrate local volatility extensions of stochastic volatility models, e.g. the local vol extension of the Heston model. But the treatment of the boundary conditions – especially at zero instantaneous variance – is notoriously difficult if the Feller constraint

of the square root process for the variance


is violated. The corresponding Fokker-Planck forward equation
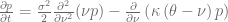
describes the time evolution of the probability density function p and the boundary at the origin 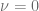

diverges with
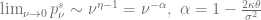
and the zero flow boundary condition at the origin
![\left.\left[ \frac{\sigma^2}{2}\frac{\partial}{\partial \nu} (\nu p) + \kappa(\nu-\theta)p\right]\right|_{\nu=0} = 0](https://s0.wp.com/latex.php?latex=%5Cleft.%5Cleft%5B+%5Cfrac%7B%5Csigma%5E2%7D%7B2%7D%5Cfrac%7B%5Cpartial%7D%7B%5Cpartial+%5Cnu%7D+%28%5Cnu+p%29+%2B+%5Ckappa%28%5Cnu-%5Ctheta%29p%5Cright%5D%5Cright%7C_%7B%5Cnu%3D0%7D+%3D+0+&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
becomes hard to track numerically. Rewriting the partial differential equation in terms of 
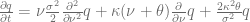
The corresponding zero flow boundary condition in q reads as follows
![\left.\left[ \nu\frac{\sigma^2}{2}\frac{\partial}{\partial \nu} q + \kappa\nu q\right]\right|_{\nu=0} = 0](https://s0.wp.com/latex.php?latex=%5Cleft.%5Cleft%5B+%5Cnu%5Cfrac%7B%5Csigma%5E2%7D%7B2%7D%5Cfrac%7B%5Cpartial%7D%7B%5Cpartial+%5Cnu%7D+q+%2B+%5Ckappa%5Cnu+q%5Cright%5D%5Cright%7C_%7B%5Cnu%3D0%7D+%3D+0+&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
The first step in order to apply the boundary condition is to discretize the transformed Fokker-Planck equation in space direction on a non-uniform grid

![\frac{\partial q_i}{\partial t} = \alpha_iq_{i-1}+\beta_iq_i+\gamma_iq_{i+1]}](https://s0.wp.com/latex.php?latex=%5Cfrac%7B%5Cpartial+q_i%7D%7B%5Cpartial+t%7D+%3D+%5Calpha_iq_%7Bi-1%7D%2B%5Cbeta_iq_i%2B%5Cgamma_iq_%7Bi%2B1%5D%7D+&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
with
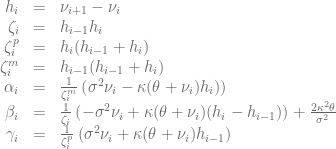
Next step is to discretize the zero flow boundary condition using a second order forward discretization [3] for the derivative 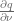
![\left.\left[ \nu\frac{\sigma^2}{2}\frac{\partial}{\partial \nu} q + \kappa\nu q\right]\right|_{\nu=\nu_{i-1}} \approx a_iq_{i-1} + b_iq_{i} + c_iq_{i+1} = 0](https://s0.wp.com/latex.php?latex=%5Cleft.%5Cleft%5B+%5Cnu%5Cfrac%7B%5Csigma%5E2%7D%7B2%7D%5Cfrac%7B%5Cpartial%7D%7B%5Cpartial+%5Cnu%7D+q+%2B+%5Ckappa%5Cnu+q%5Cright%5D%5Cright%7C_%7B%5Cnu%3D%5Cnu_%7Bi-1%7D%7D+%5Capprox+a_iq_%7Bi-1%7D+%2B+b_iq_%7Bi%7D+%2B+c_iq_%7Bi%2B1%7D+%3D+0+&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
with
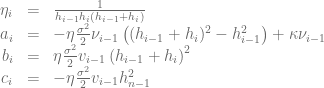
Now the value 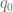
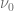
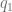
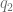
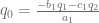
This equation can be used to remove the boundary value 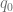
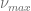
The following parameters of the square-root process will be used to test the different boundary conditions.
The uniform grid 

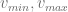
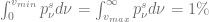
The grid covers 98% of the distribution and this value would not change over time if the boundary conditions are satisfied without discretiszation errors. To test the magnitude of the discretization errors we let the initial solution evolve over one year using 100 time steps with the Crank-Nicolson scheme. The resulting solution 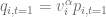
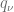

servers as a quality indicator for the discretization errors of the boundary condition.
As can be seen in the diagram below if 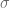

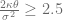
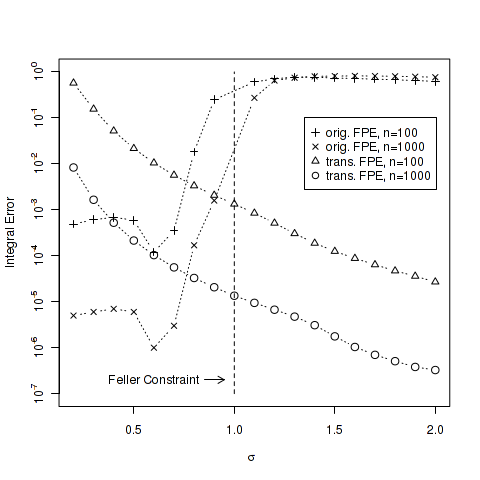
The same techniques can be used to solve the Fokker-Planck equation for the Heston model. The code for the numerical tests is available in the latest QuantLib version from the SVN trunk. The diagram is based on the test FDHestonTest::testSquareRootEvolveWithStationaryDensity.
[1] A. Dragulescu, V. Yakovenko, Probability distribution of returns in the Heston model with stochastic volatility
[2] V. Lucic, Boundary Conditions for Computing Densities in Hybrid Models via PDE Methods
[3] P. Lermusiaux, Numerical Fluid Mechanics, Lecture Note 14, Page 5
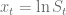
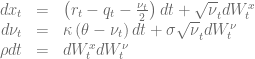

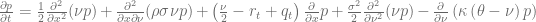

 denotes the Dirac delta distribution. A semi-closed form solution for this problem is presented in [1]. When solving the Fokker-Planck forward equation special care must be taken with respect to the boundary conditions, especially if the Feller constraint
denotes the Dirac delta distribution. A semi-closed form solution for this problem is presented in [1]. When solving the Fokker-Planck forward equation special care must be taken with respect to the boundary conditions, especially if the Feller constraint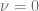 is instantaneously attainable. A generalisation of Feller’s zero-flux boundary condition should be applied at the origin [2].
is instantaneously attainable. A generalisation of Feller’s zero-flux boundary condition should be applied at the origin [2].![\left.\left[ \frac{\sigma^2}{2}\frac{\partial}{\partial \nu} (\nu p) + \kappa(\nu-\theta)p + \rho\nu\sigma\frac{\partial p}{\partial x}\right]\right|_{\nu=0} = 0, \ \forall x\in \mathbb{R}^+](https://s0.wp.com/latex.php?latex=%5Cleft.%5Cleft%5B+%5Cfrac%7B%5Csigma%5E2%7D%7B2%7D%5Cfrac%7B%5Cpartial%7D%7B%5Cpartial+%5Cnu%7D+%28%5Cnu+p%29+%2B+%5Ckappa%28%5Cnu-%5Ctheta%29p+%2B+%5Crho%5Cnu%5Csigma%5Cfrac%7B%5Cpartial+p%7D%7B%5Cpartial+x%7D%5Cright%5D%5Cright%7C_%7B%5Cnu%3D0%7D+%3D+0%2C+%5C+%5Cforall+x%5Cin+%5Cmathbb%7BR%7D%5E%2B+&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
 for
for  [3].
[3].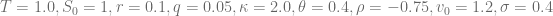

 and this changes the shape of the solution completely.
and this changes the shape of the solution completely.


 for typical partial differential equations in financial engineering. Unfortunately if these schemes are used together with dynamic programming to price America options the second order convergence is destroyed by the first order convergence of the dynamic programming step.
for typical partial differential equations in financial engineering. Unfortunately if these schemes are used together with dynamic programming to price America options the second order convergence is destroyed by the first order convergence of the dynamic programming step. .
.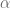 does not depend on
does not depend on 
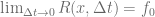
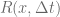 is n+1. The order does not depend on the particular value of x but often x is chosen to be two. This simple trick can be extended to the case where n is unknown or the Richardson extrapolation can be used m times to increase the order of convergence to n+m [2].
is n+1. The order does not depend on the particular value of x but often x is chosen to be two. This simple trick can be extended to the case where n is unknown or the Richardson extrapolation can be used m times to increase the order of convergence to n+m [2].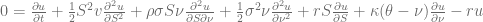
 .
.
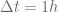 anyhow. This step size is small enough for the implicit Euler scheme to obtain a very good accuracy. The explicit Euler scheme is numerically unstable, even if
anyhow. This step size is small enough for the implicit Euler scheme to obtain a very good accuracy. The explicit Euler scheme is numerically unstable, even if 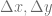 and
and  .
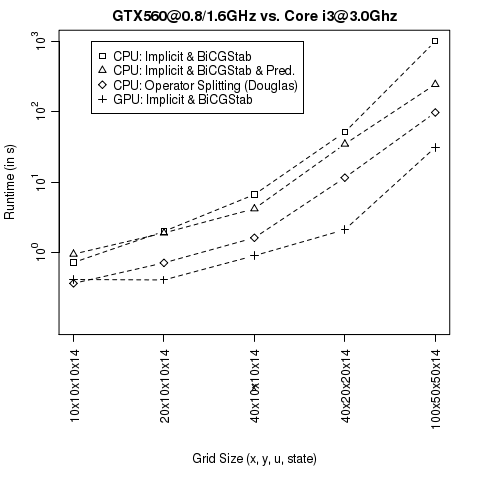
.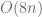 operations. The corresponding preconditioner can be seen as a natural extension of the diagonal preconditioner. Experiments on a CPU indicate that the tridiagonal preconditioner leads to a significant speed-up for our VPP pricing problem. The upcoming CUSPARSE library of the
operations. The corresponding preconditioner can be seen as a natural extension of the diagonal preconditioner. Experiments on a CPU indicate that the tridiagonal preconditioner leads to a significant speed-up for our VPP pricing problem. The upcoming CUSPARSE library of the  and a maturity of 4 weeks (corresponds to
and a maturity of 4 weeks (corresponds to 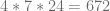 exercise steps). Therefore in addition to the three dimensions for the stochastic model the problem has a fourth dimension of size
exercise steps). Therefore in addition to the three dimensions for the stochastic model the problem has a fourth dimension of size  to solve the optimization problem via dynamic programming.
to solve the optimization problem via dynamic programming.

 is denoting the market instantaneous forward rate at time 0 for the maturity T (see. e.g. [1]). The Hull-White model can be seen as a one-dimensional simplification of the G2++ model. The corresponding partial differential equation (PDE) can be derived using the
is denoting the market instantaneous forward rate at time 0 for the maturity T (see. e.g. [1]). The Hull-White model can be seen as a one-dimensional simplification of the G2++ model. The corresponding partial differential equation (PDE) can be derived using the 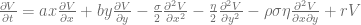


 operations instead of
operations instead of  operations required by the Gaussian elimination. But it is not easy to parallelize the Thomas algorithm.
operations required by the Gaussian elimination. But it is not easy to parallelize the Thomas algorithm.
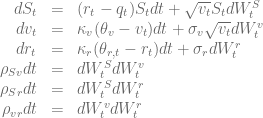
![\begin{array}{|c|c|c|c|c|c|c|c|c|} \hline {\rm Model} & v_0 & \kappa_v & \theta_v & \sigma_v & \rho_{Sv} & r & q & \mbox{Ref} \\ \hline \hline {\rm't\ Hout\ Case\ 1}& 0.04& 1.5& 0.04& 0.3& -0.9& 0.025& 0.0 &[2]\\ {\rm't\ Hout\ Case\ 2} & 0.12& 3.0& 0.12& 0.04& 0.6& 0.01& 0.04 &[2]\\ {\rm't\ Hout\ Case\ 3}& 0.0707&0.6067& 0.0707& 0.2928& -0.7571& 0.03& 0.0 & [2]\\ {\rm't\ Hout\ Case\ 4}& 0.06& 2.5& 0.06& 0.5& -0.1& 0.0507& 0.0469 &[2]\\ {\rm Ikonen\ Toivanen}& 0.0625& 5& 0.16& 0.9& 0.1& 0.1& 0.0 &[3]\\ {\rm Kahl\ J\ddot{a}ckel}& 0.16& 1.0& 0.16& 2.0& -0.8& 0.0& 0.0 &[4]\\ {\rm Equity Case }& 0.07& 2.0& 0.04& 0.55& -0.8& 0.03& 0.035 &\\ {\rm High Correlation}& 0.07& 1.0& 0.04& 0.55& 0.9& 0.02& 0.04& \\ {\rm small\ \sigma_v}& 0.07& 1.0& 0.04& 0.001& -0.75& 0.04& 0.03& \\ \kappa_v=\sigma_v\rho_{Sv}& 0.07& 0.4& 0.04& 0.5& 0.8& 0.03& 0.03 &\\ \hline \end{array}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Barray%7D%7B%7Cc%7Cc%7Cc%7Cc%7Cc%7Cc%7Cc%7Cc%7Cc%7C%7D+%5Chline+%7B%5Crm+Model%7D+%26+v_0+%26+%5Ckappa_v+%26+%5Ctheta_v+%26+%5Csigma_v+%26+%5Crho_%7BSv%7D+%26+r+%26+q+%26+%5Cmbox%7BRef%7D+%5C%5C+%5Chline+%5Chline+%7B%5Crm%27t%5C+Hout%5C+Case%5C+1%7D%26+0.04%26+1.5%26+0.04%26+0.3%26+-0.9%26+0.025%26+0.0+%26%5B2%5D%5C%5C+%7B%5Crm%27t%5C+Hout%5C+Case%5C+2%7D+%26+0.12%26+3.0%26+0.12%26+0.04%26+0.6%26+0.01%26+0.04+%26%5B2%5D%5C%5C+%7B%5Crm%27t%5C+Hout%5C+Case%5C+3%7D%26+0.0707%260.6067%26+0.0707%26+0.2928%26+-0.7571%26+0.03%26+0.0+%26+%5B2%5D%5C%5C+%7B%5Crm%27t%5C+Hout%5C+Case%5C+4%7D%26+0.06%26+2.5%26+0.06%26+0.5%26+-0.1%26+0.0507%26+0.0469+%26%5B2%5D%5C%5C+%7B%5Crm+Ikonen%5C+Toivanen%7D%26+0.0625%26+5%26+0.16%26+0.9%26+0.1%26+0.1%26+0.0+%26%5B3%5D%5C%5C+%7B%5Crm+Kahl%5C+J%5Cddot%7Ba%7Dckel%7D%26+0.16%26+1.0%26+0.16%26+2.0%26+-0.8%26+0.0%26+0.0+%26%5B4%5D%5C%5C+%7B%5Crm+Equity+Case+%7D%26+0.07%26+2.0%26+0.04%26+0.55%26+-0.8%26+0.03%26+0.035+%26%5C%5C+%7B%5Crm+High+Correlation%7D%26+0.07%26+1.0%26+0.04%26+0.55%26+0.9%26+0.02%26+0.04%26+%5C%5C+%7B%5Crm+small%5C+%5Csigma_v%7D%26+0.07%26+1.0%26+0.04%26+0.001%26+-0.75%26+0.04%26+0.03%26+%5C%5C+%5Ckappa_v%3D%5Csigma_v%5Crho_%7BSv%7D%26+0.07%26+0.4%26+0.04%26+0.5%26+0.8%26+0.03%26+0.03+%26%5C%5C+%5Chline+%5Cend%7Barray%7D&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
 and
and 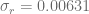 . The equity interest rate correlation is
. The equity interest rate correlation is 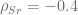 , interest rates and stochastic volatility aren’t correlated
, interest rates and stochastic volatility aren’t correlated  The benchmark call options have maturity of 5 years, underlying at time
The benchmark call options have maturity of 5 years, underlying at time 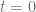 is
is 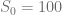 and possible strikes are
and possible strikes are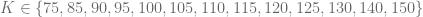 .
. strikes and
strikes and 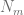 models.
models.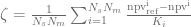
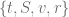 . and with control variate based on the semi–closed Heston Model. Clearly the Douglas scheme is the worst performer, the (modified) Craig-Sneyd and modified Hundsdorfer-Verwer scheme are the winner.
. and with control variate based on the semi–closed Heston Model. Clearly the Douglas scheme is the worst performer, the (modified) Craig-Sneyd and modified Hundsdorfer-Verwer scheme are the winner.


![\begin{array}{rcl} rV&=&\frac{\partial V}{\partial t}+\frac{\sigma_x^2}{2}\frac{\partial^2 V}{\partial x^2}-\alpha x\frac{\partial V}{\partial x}-\beta y \frac{\partial V}{\partial y} \\[6pt]&+&\frac{\sigma_u^2}{2}\frac{\partial^2 V}{\partial u^2}- \kappa u\frac{\partial V}{\partial u} +\rho\sigma_x\sigma_u\frac{\partial^2 V}{\partial x\partial u}\\[6pt] &+&\lambda\int_\mathbb{R}\left(V(x,y+z,u,t)-V(x,y,u,t) \right )\omega(z)dz \\ \end{array}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Barray%7D%7Brcl%7D+rV%26%3D%26%5Cfrac%7B%5Cpartial+V%7D%7B%5Cpartial+t%7D%2B%5Cfrac%7B%5Csigma_x%5E2%7D%7B2%7D%5Cfrac%7B%5Cpartial%5E2+V%7D%7B%5Cpartial+x%5E2%7D-%5Calpha+x%5Cfrac%7B%5Cpartial+V%7D%7B%5Cpartial+x%7D-%5Cbeta+y+%5Cfrac%7B%5Cpartial+V%7D%7B%5Cpartial+y%7D+%5C%5C%5B6pt%5D%26%2B%26%5Cfrac%7B%5Csigma_u%5E2%7D%7B2%7D%5Cfrac%7B%5Cpartial%5E2+V%7D%7B%5Cpartial+u%5E2%7D-+%5Ckappa+u%5Cfrac%7B%5Cpartial+V%7D%7B%5Cpartial+u%7D+%2B%5Crho%5Csigma_x%5Csigma_u%5Cfrac%7B%5Cpartial%5E2+V%7D%7B%5Cpartial+x%5Cpartial+u%7D%5C%5C%5B6pt%5D+%26%2B%26%5Clambda%5Cint_%5Cmathbb%7BR%7D%5Cleft%28V%28x%2Cy%2Bz%2Cu%2Ct%29-V%28x%2Cy%2Cu%2Ct%29+%5Cright+%29%5Comega%28z%29dz+%5C%5C+%5Cend%7Barray%7D&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
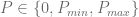 has
has 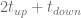 different states.
different states.

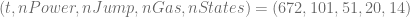 .
. exercise opportunities. The number of overall exercised swing opportunities is constraint by
exercise opportunities. The number of overall exercised swing opportunities is constraint by .
.

{kind=link}
{kind=link}
{kind=link}
{kind=link}