
As outlined in Solving Sparse Linear Systems using CUSP and CUDA a VPP pricing problem can be solved on a GPU using finite difference methods based on the implicit Euler scheme. The matrix inversion is carried out on the GPU using the BiCGStab solver of the numerical library cusp [1]. The optimal exercise problem for the VPP can be solved using dynamic programming for every time slice on the GPU (see [2]).
The lower convergence order in 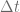
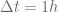
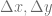

Clearly the matrix inversion dominates the overall runtime of the pricing routine. Preconditioning is a standard technique to improve the performance of the involved BiCGStab algorithm. The cusp library supports a set of suited preconditioner for this problem.
- Diagonal: preconditioning is very inexpensive to use, but has often limited effectiveness.
- Approximate Inverse: Non-symmetric Bridson with different dropping strategies.
- Smoothed Aggregation: Algebraic Multi-grid preconditioner based on smoothed aggregation.
On a CPU QuantLib supports preconditioning based on the Thomas algorithm. This algorithm solves a tridiagonal matrix with 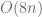
The testbed is a VPP contract with 
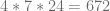

The following diagram shows the different run-times of the algorithms on a GPU and a CPU.
 The fastest algorithm on the GPU (implicit Euler scheme with BiCGStab and tridiagonal preconditioner) outperforms the best CPU implementation (operator splitting based on the Douglas scheme) roughly by a factor of ten. The non-symmetric Bridson preconditioner with the dropping strategy from Lin & More on the GPU is the second best algorithm but it ran out of memory on larger grids. The diagonal preconditioner slows down the overall performance on the GPU and the BiCGStab algorithm with the smoothed aggregation preconditioner did not converge.
The fastest algorithm on the GPU (implicit Euler scheme with BiCGStab and tridiagonal preconditioner) outperforms the best CPU implementation (operator splitting based on the Douglas scheme) roughly by a factor of ten. The non-symmetric Bridson preconditioner with the dropping strategy from Lin & More on the GPU is the second best algorithm but it ran out of memory on larger grids. The diagonal preconditioner slows down the overall performance on the GPU and the BiCGStab algorithm with the smoothed aggregation preconditioner did not converge.
[1] cusp, Generic Parallel Algorithms for Sparse Matrix and Graph Computations
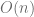 operations instead of
operations instead of 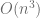 operations required by the Gaussian elimination. But it is not easy to parallelize the Thomas algorithm.
operations required by the Gaussian elimination. But it is not easy to parallelize the Thomas algorithm.

{kind=link}
{kind=link}