
Even the pricing of a simple virtual power plant (VPP) is challenging. Main reasons are the high number of possible states of the VPP and the large number of possible exercise dates because often a VPP is priced as a bermudan-style option with hourly exercise rights. The implementation effort for an exact pricing engine based on finite difference methods (see e.g.[1]) or based on least squares Monte-Carlo is comparable large. As shown in [1] Monte-Carlo combined with perfect foresight optimization can result in a very good approximation. The algorithm consists of a Monte-Carlo path generator and a dynamic programming optimization part, which calculates the optimal load schedule plan for each path separately. The stochastic processes involved are outlined in [1].
The CUDA based GPU implementation is available here. It depends on the latest QuantLib version from the SVN trunk or the upcoming QuantLib 1.2 release and CUDA 4.0. The corresponding C++ implementation is a speed-optimized version of the test-case VPPTest::testVPPPricing. This version also supports multi-threading. The following hardware was used to compare both implementations:
- CPU: Core i5@3.0 GHz, quad-core
- GPU: GTX560@810/1620MHz, 336 cores
As can be seen in the diagram below the GPU outperforms the CPU roughly by a factor 100 for single precision and a factor of 50 if the GPU is using double precision.

The CUDA implementation consists of the following files:
gpuvpppricingengine.hpp / gpuvpppricingengine.cpp
A QuantLib pricing engine for a simple VPP based on a Monte-Carlo simulation and perfect foresight optimization via dynamic programming. The physical size of the Monte-Carlo simulation is controlled by the following parameters of the constructor
- Size nSimulations: number of Monte-Carlo simulations carried out.
- bool antithetic: enables/disables antithetic sampling
- Size blockSize: number of threads in a CUDA block.
- Size gridSize: number of CUDA blocks that are grouped together in a simulation kernel.
gpuvpppricingengine_kernel.hpp
gpuvpppricingengine_kernel.cu/ gpuvpppricingengine_kernel.def
The CUDA implementation consists of two kernels. The first kernel is the Monte-Carlo path generator, which calculates the paths on hourly granularity and stores them in the global memory of the graphic card.. The technics used are outlined e.g. in [2], [3] and [4]. The second kernel performs the optimization of the load schedule based on dynamic programming. The memory layout of this step depends on the number of possible states of the VPP because every possible state is stored in the shared memory of the GPU. The number of states is given by 
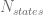
cudatype.hpp
defines basic CUDA types, especially the typedef for the type “real” can be used to compile the code either for single or double precision.
gpurand.hpp
C++ interface for a GPU random number generator
gpucurand.hpp / gpucurand.cpp / gpucurand_kernel.hpp / gpucurand_kernel.cu
implementation of the GPURand interface based on the CURAND library, which is part of CUDA 4.0.
[1] this blog, VPP Pricing III: Exact Pricing based on Finite Difference Methods.
[2] L. Howes, D. Thomas, Efficient Random Number Generation and Application Using CUDA.
[3] A. Bernemann, R. Schreyer, K. Spanderen, Accelerating Exotic Option Pricing and Model Calibration Using GPUs
[4] M. Joshi, Graphical Asian Options

Nice article. Its realy nice. More information help me.